|
Shaofeng Yin (殷绍峰) I'm a senior undergraduate student at Peking University, majoring in artificial intelligence (Zhi Class). In Spring 2025, I visited Berkeley AI Research and had a wonderful time there. My early research focused on human-object interaction detection (HOID) in computer vision. As vision-language models (VLMs) have grown impressively powerful, I've become deeply interested in the study of multimodal agents. In my life, I have a deep appreciation for art, literature, and philosophy. I'm also deeply commited to volunteer teaching programs. I was passionate about competitive programming and earned the title of Codeforces Master at the age of 15. |

|
📚 Selected Publications |
|
|
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Shaofeng Yin, Jiaxin Ge, Zora Zhiruo Wang, Xiuyu Li, Michael J. Black, Trevor Darrell, Angjoo Kanazawa, Haiwen Feng ECCV, 2026 project page / arXiv / tweet Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. |
|
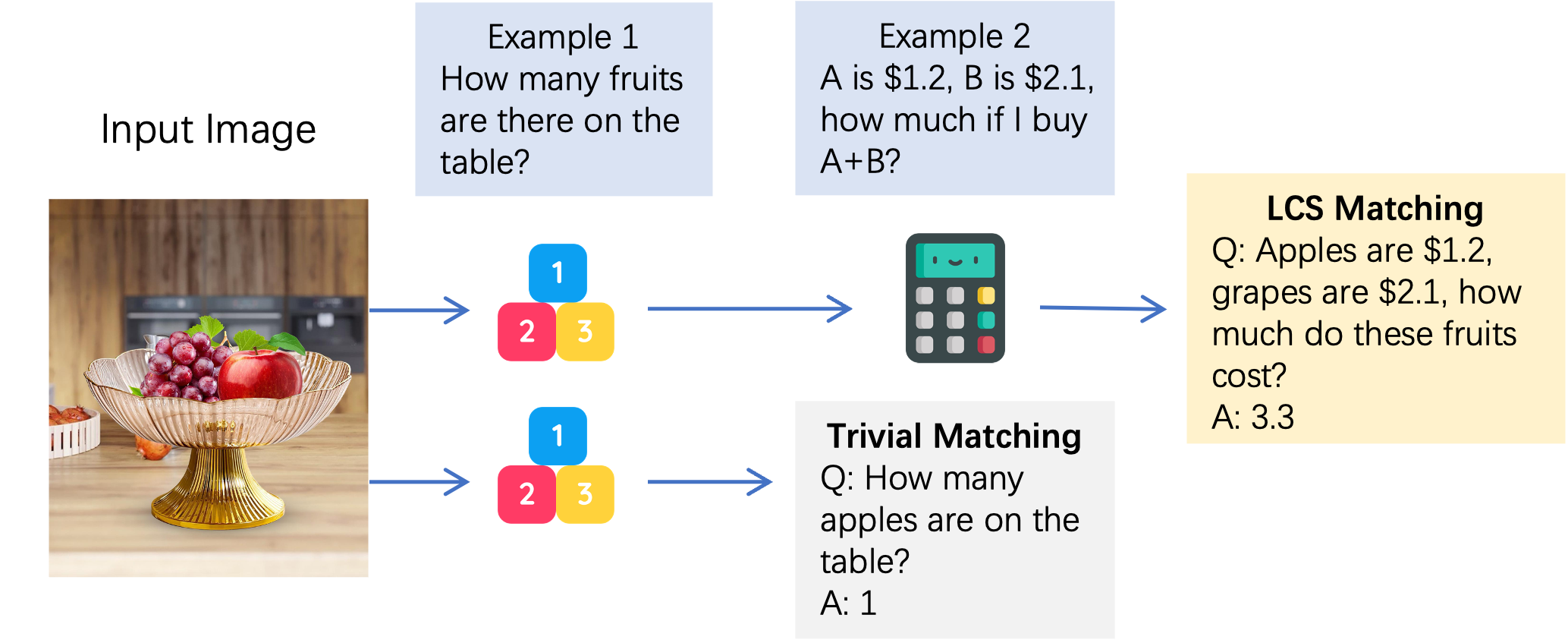
ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools
Shaofeng Yin, Ting Lei, Yang Liu ICCV, 2025 project page / arXiv Recent benchmarks reveal significant gaps in real-world tool-use proficiency, particularly in functionally diverse multimodal settings requiring multi-step reasoning. To bridge this gap, we propose ToolEngine, a novel data generation pipeline that employs Depth-First Search (DFS) with a dynamic in-context example matching mechanism to simulate human-like tool-use reasoning. |
🏆 Selected Awards |
|
2025: First Prize in CVPR International CulturalVQA Benchmark Challenge
2025: SenseTime Scholarship (30/year in China) 2024: National Scholarship (Highest honor for undergraduates) |
📸 Selected Photography |










|
The template is stole from Jon Barron. |